De meest gebruikte opbouw in business intelligence, predictive analitics en analytics modellen is de moeilijkheidsgraad: 1) descriptive, 2) diagnostic, 3) predictive en 4) prescriptive. Deze schaal vertelt iets over de volwassenheid van het gebruik van data door de organisatie. Deze modellen zijn helaas zo abstract dat ze niet gebruikt kunnen worden om voor een specifieke taak een concreet stappenplan te creëren om van descriptieve analytics naar prescriptieve analytics te komen. Dit komt mede door het feit dat de modellen als marketinginstrument worden gebruikt of op zichzelf staan zonder een achterliggende methode. Een model dat niet op zichzelf staat en een achterliggende methode kent is de data driehoek van EDM (Figuur 1), welke in dit artikel zal worden toegelicht. De data-driehoek is opgebouwd uit een drietal perspectieven en bijbehorende cycli.
In het midden van de data-driehoek zijn de data geplaatst. Er kan op verschillende manieren naar deze data worden gekeken. Dit zijn de perspectieven waarin een onderscheid wordt gemaakt. De data-driehoek onderkent drie verschillende perspectieven: 1) het proces-perspectief, 2) het beslissings-perspectief en 3) het kerngetallen-perspectief.
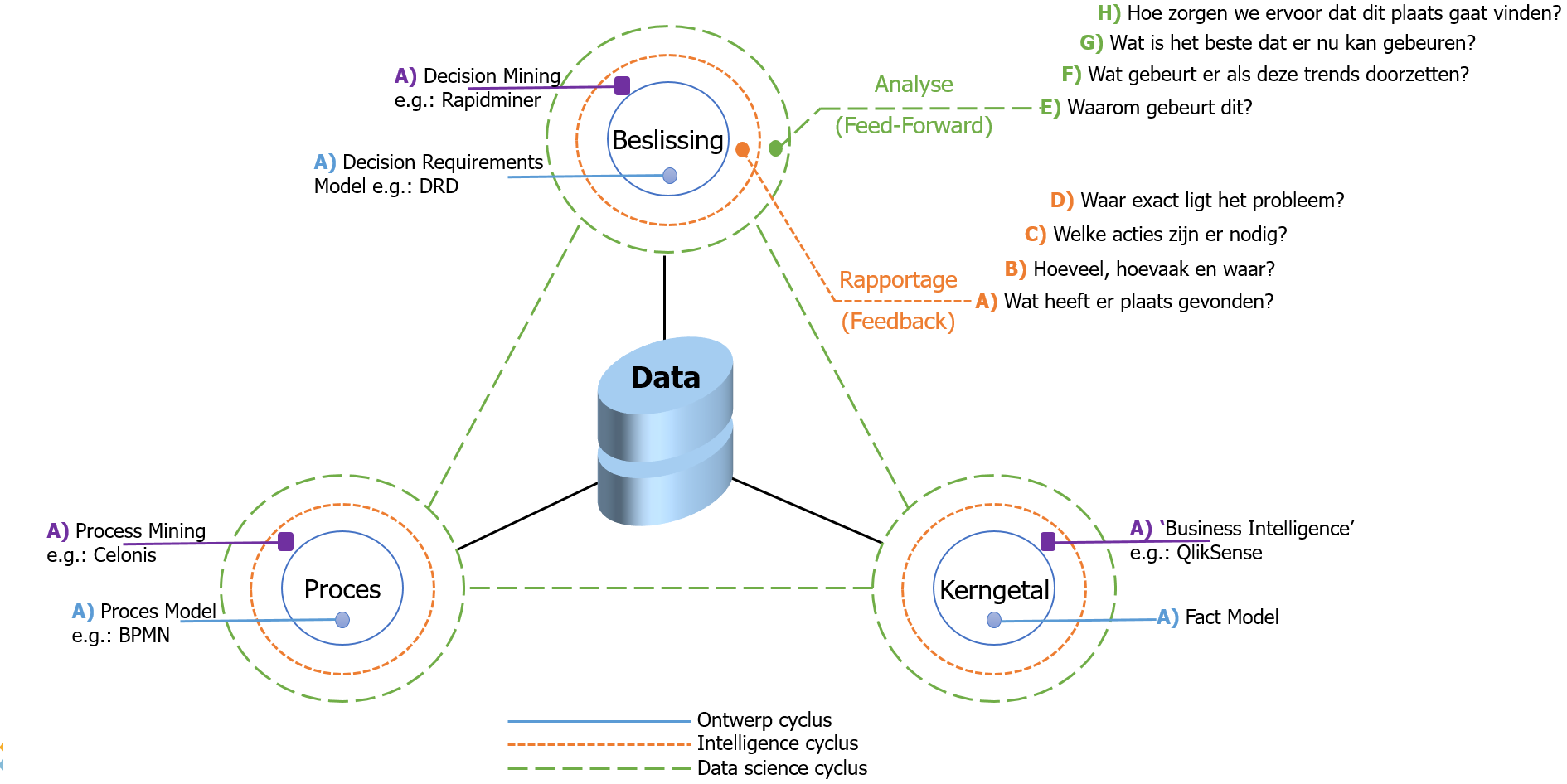
Figuur 1: De data-driehoek
Het proces-perspectief focust zich op de sequentie van activiteiten om een bepaald doel te bereiken. Voorbeelden van processen zijn 1) aanvraag kinderbijslag, 2) aanvraag werkeloosheidsuitkering en 3) verwerken inkomstenbelasting. Het beslissings-perspectief focust zich op het trekken van een conclusie op basis van feiten. Voorbeelden van beslissingen zijn 1) het bereken van de hoogte van de kinderbijslag en 2) bepalen van de duur van de kinderbijslag en 3) berekenen van de hoogte van de omzetbelasting. Het getallen-perspectief focust zich op kerngetallen. Voorbeelden van kerngetallen zijn: 1) aantal WW aanvragen, 2) aantal kinderbijslag aanvragen en 3) totaal uitgekeerde euro’s voor de kinderbijslag.
Bij elk perspectief onderkend het model drie cycli: de ontwerp-cyclus, de intelligence-cyclus en de data science cyclus. Elke cyclus kent zijn eigen dynamiek en er staan per cyclus andere vragen centraal die beantwoordt dienen te worden. Bij elk perspectief staan wel dezelfde type vragen centraal maar deze vragen worden vanuit het geselecteerde perspectief bekeken. In dit artikel wordt met name ingegaan op het beslissings-perspectief.
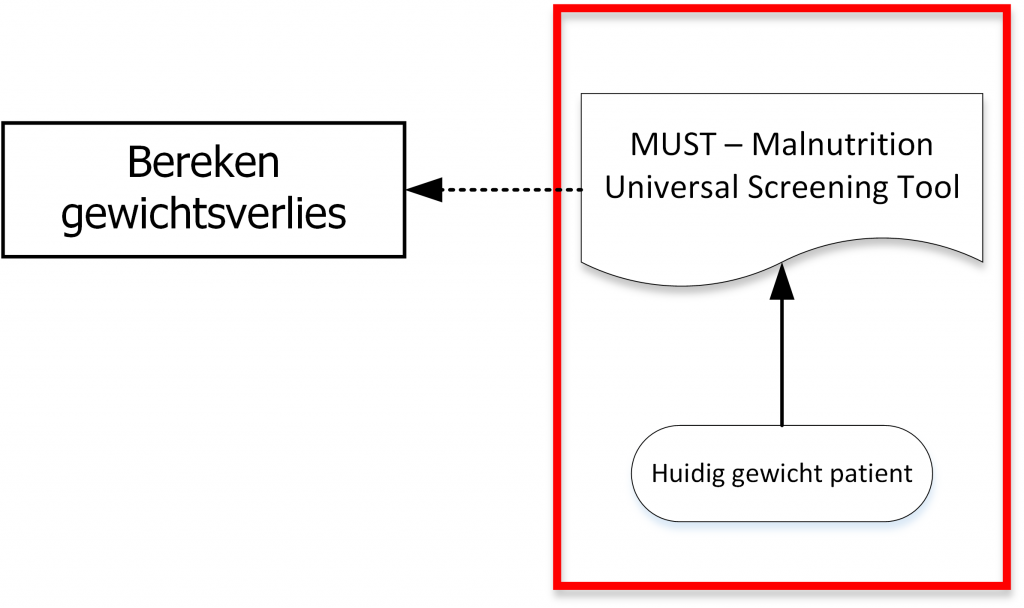
In de ontwerpcyclus wordt de beslissing ontworpen en gespecificeerd. Afhankelijk van de voorspelbaarheid van de beslissing kent de ontwerpcyclus een specifiek aantal activiteiten en resultaat. Wanneer de beslissing een hoge mate van voorspelbaarheid heeft kan een beslistabel of bedrijfsregelset worden gespecificeerd, zie Figuur 2 als voorbeeld. Wanneer een beslissing een lage mate van voorspelbaarheid heeft kan er gebruik gemaakt worden van neurale netwerken of ander soortige algoritmes. Nadat de beslissing is ontworpen en gespecificeerd wordt deze in productie gebracht en gaat de volgende cyclus lopen: de intelligence cyclus.

Figuur 2: Voorbeeld beslistabel – mate van verwijtbaarheid ten tijde van overtreden
De intelligence cyclus heeft als doel ‘standaard’ vragen te beantwoorden over de uitvoering van de beslissing. In de meeste data science literatuur wordt de intelligence cyclus vaak beschreven als descriptieve statistiek. De intelligence cyclus focust zich met name op feedback. Deze cyclus dient standaard te worden ingericht voor elke beslissing die in productie wordt gebracht en wordt uitgevoerd. Het type vragen waarop wordt ingegaan zijn:
- Wat is er gebeurd?
- Hoe vaak heeft het plaatsgevonden?
- Welke acties zijn er op dit moment nodig?
- Waar ligt het exacte probleem?
Wanneer we deze vragen ‘finetunen’ naar het beslissings-perspectief zijn twee voorbeeldvragen van toepassing:
- Wat zijn de varianten per beslissing?
- Hoeveel uitvoeringen zijn er per varianten per beslissing?
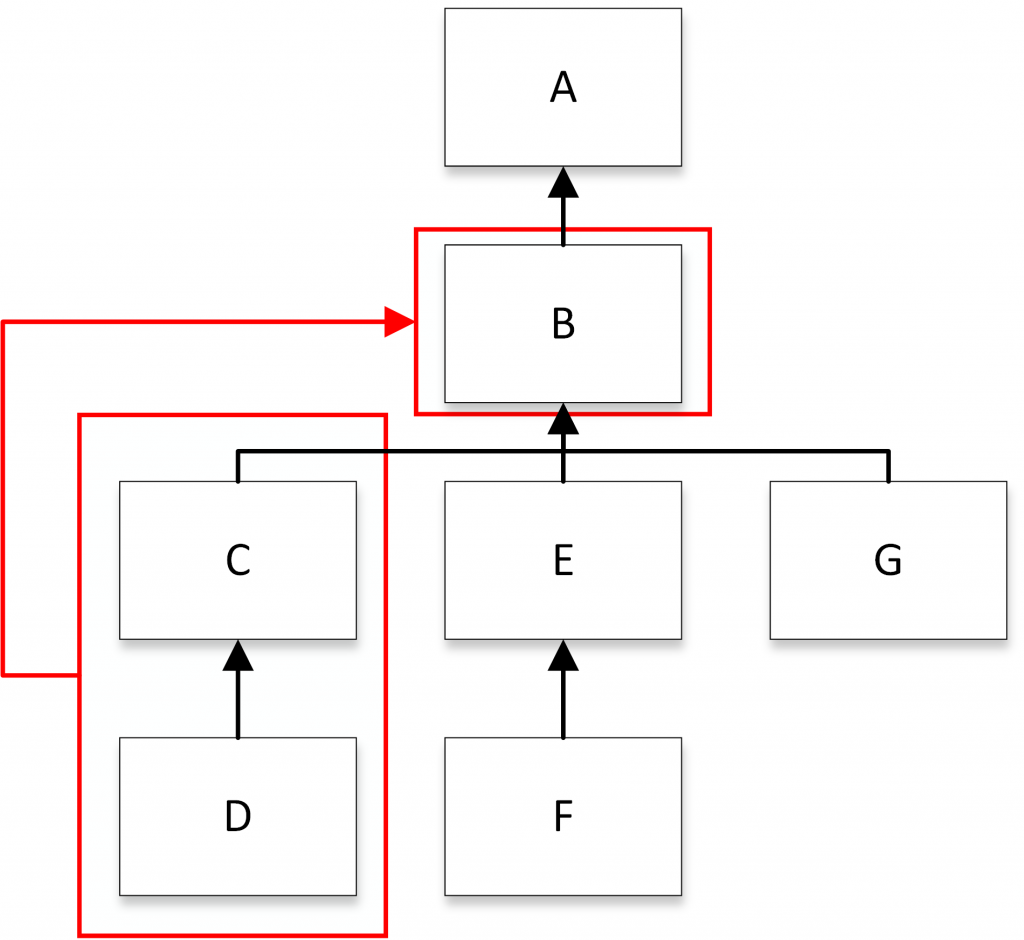
Het antwoord op deze twee vragen wordt grafisch weergegeven in Figuur 3. Dit figuur representeert de daadwerkelijk uitgevoerde beslissingen die op basis van Figuur 2 zijn gemaakt. Regel 1, in Figuur 2 kent de volgende eigenschappen: Het conditie feittype “verwijtbaarheid ontbreekt geheel [wet]” kent de feitwaarde “ja”, de overige conditiefeittypen zijn niet ingevuld en de conclusie “mate van verwijtbaarheid ten tijde van overtreden” kent de feitwaarde “geheel ontbreken van verwijtbaarheid”. In Figuur 3 wordt deze variant (uitvoeringspad) weergegeven bovenaan het model, van het donkerblauwe blokjes “verwijtbaarheid ontbreekt” tot het lichtblauwe blokje: “geheel ontbreken van verwijtbaarheid”. De dikte van de lijn geeft aan om hoeveel cases het gaat, in dit geval 20% van de 128.000 uitgevoerde beslissingen. Figuur 3 geeft ook aan dat elk ander pad begint met “verwijtbaarheid ontbreekt niet”, dit zien we ook terug in de beslistabel uit Figuur 2, waar de bedrijfsregels 2 tot en met 6 elk beginnen met het conditie feittype “verwijtbaarheid ontbreekt geheel [wet]” en de feitwaarde “nee”. Elke vraag vergt zijn eigen visualisaties. Voor andere vragen dan gesteld in dit artikel zijn andere visualisaties beschikbaar, maar hier gaan we in dit artikel niet op in.

Figuur 3: Analyse van de beslissing
Zoals gezegd dient de intelligence cylus bij elke geïmplementeerde beslissing standaard te worden meegeleverd. Naast de intelligence cyclus bestaat er ook een data science cyclus. In de meeste data science literatuur wordt de data science cyclus vaak beschreven als diagnostic, predictive en prescriptive. Waar de intelligence cyclus focust op de standaard vragen, focust de data science cyclus op feed-forward en meer geavanceerde vragen. In de data science cyclus worden de volgende type vragen beantwoord:
- Waarom gebeurt dit?
- Wat gebeurt er als dit doorgaat? Forecasting / extrapolation?
- Wat gebeurt er hierna? Wat is het beste dat nu kan gebeuren?
- Hoe gaan we er voor zorgen dat dit gebeurt?
Wanneer we deze vragen ‘finetunen’ naar het beslissings-perspectief zijn twee voorbeeldvragen van toepassing:
- Wat is het resultaat van de beslissing als deze dingen doorgaan?
- Hoe zorgen we dat deze trend niet doorzet?
Een specifiek voorbeeld van de twee bovenstaande vragen zijn de gekoppelde beslissingen van de burger om te gaan klagen over stankoverlast vanwege afval in een prullenbak en de beslissing van de gemeente om de prullenbak te legen. Uit data-analyse blijkt dat wanneer de hoeveelheid bedorven voedsel in een prullenbak een bepaalde hoogte bereikt, burgers gaan klagen over stankoverlast. Deze beslissing van de burger wordt gemonitord en ook de gekoppelde beslissing om de prullenbak te legen. Beide beslissingen zijn bij de vuilnisverwerking op een dashboard te zien. Zolang de beslissing om te klagen op groen staat gebeurd er niets, maar de vuilnis verwerking weet ook dat wanneer er een bepaalde hoeveelheid bedorven voedsel bij komt, de beslissing op rood komt te staan. Het dashboard geeft ook aan hoelang het gemiddeld duurt voordat de maximale hoeveelheid bedorven voedsel in de prullenbak terecht komt en hoelang het duurt voordat burgers gaan klagen. Daarnaast geeft het dashboard aan welke van de huidige data elementen leiden tot een positieve beslissing en welke tot een negatieve beslissing. Om te voorkomen dat de meldingen tot stankoverlast niet toenemen of niet voorkomen (Zie de vraag: hoe zorgen we dat deze trend niet doorzet) neemt de vuilnisverwerker (of het onderliggende systeem) zelf de beslissing om een vuilniswagen langs te sturen. In de zomer versnelt de stankoverlast zich bij bepaalde prullenbakken door meer bedorven voedsel. Om dit te voorkomen past de vuilnisverwerker (of het onderliggende systeem) preventief de routes zodanig aan dat deze prullenbakken vaker worden geleegd om stankoverlast tegen te gaan.
Mede-Auteur: Koen Smit