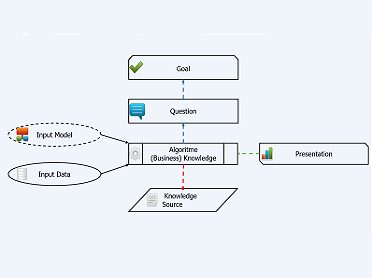
Sinds september 2015 is de ‘business rule management wereld’ / ‘decision management wereld’ weer een standaard rijker: The Decision Model and Notation (DMN). De Object Management Group (OMG) heeft deze nieuwe standaard uitgebracht met als doel een standaard taal te creëren om 1) requirements voor beslissingen en 2) de beslissingen zelf te modelleren. De adoptie van DMN heeft een wat lange aanloop gehad, maar begint nu serieuze vormen aan te nemen. Om deze reden brengen wij een vierdelige serie over DMN en het gebruik van DMN uit. In deel 1 zijn we ingegaan op de basis van The Decision Model and Notation. In dit deel (deel 2) gaan we in op de basis principes die gelden bij het creëren van een DRD.
Scenario gebaseerd eliciteren houdt in dat de Decision Requirement Diagram (DRD) wordt gemaakt op basis van een concreet scenario dat zich in de werkelijkheid afspeelt. Dit kan vanuit het gezichtspunt van de klant, bijvoorbeeld via een customer journey map. Of wanneer het een intern proces omhelst, het doorlopen van een procesbeschrijving. Op basis van een vereenvoudigd voorbeeld in de context van een ziekenhuis beschrijven we hier het proces van scenario gebaseerd eliciteren.
Scenario gebaseerd eliciteren bestaat uit zeven stappen. In dit artikel worden de volgende stappen besproken:
- Creëren van de scenarios;
- Initiële analyse van de touchpoints;
- Identificeren Identificatie-woorden;
- Identificeren zelfstandignaamwoorden;
- Identificeren onzichtbare feittypen.
- Identificeren ‘eind’ beslissing.
1. Het creëren van de scenarios
Over het maken van een gedegen scenario zijn genoeg artikelen, boeken en papers geschreven, hier wordt in dit artikel dan ook niet op in gegaan. Voor het maken van een volledig en juist DRD is het wel van belang dat alle interactie momenten met de klant worden geindentificeerd. In de praktijk betekent dit het zoeken naar, bijvoorbeeld, websites, formulieren en schermen van software applicaties.
1.1 Voorbeeld: Het creëren van de scenarios
Het voorbeeld dat wordt gebruikt in deze uitleg is het intake formulier voor een patient, in dit geval Kees, in een ziekenhuis waarneer hij wordt opgenomen, zie Figuur 1. Dit formulier wordt in het ziekenhuis gebruikt om af te leiden in hoeverre een patient kans heeft op ondervoeding. Op basis van dat gegeven wordt eventueel de diagnose, behandeling en medicatie aangepast.

Figuur 1. Intakeformulier voor Kees
2. Initiele analyse van de/het touchpoint(s)
Het doel van de initiele analyse van de touchpoints is om de potentiele beslissingen en gegevens (feittype) welke opgenomen dienen te worden in het DRD te identificeren. Hiervoor dient dit voor elke touchpoint in het proces/de customer journey te worden geanalyseerd. Tijdens de initiele analyse van de touchpoint(s) dienen drie sub-stappen te worden uitgevoerd: 1) Identificeren Identificatie-woorden, 2) Identificeren Zelfstandignaamwoorden en 3) Identificeren onzichtbare feittype.
Stap 1: Identificeren Identificatie-woorden
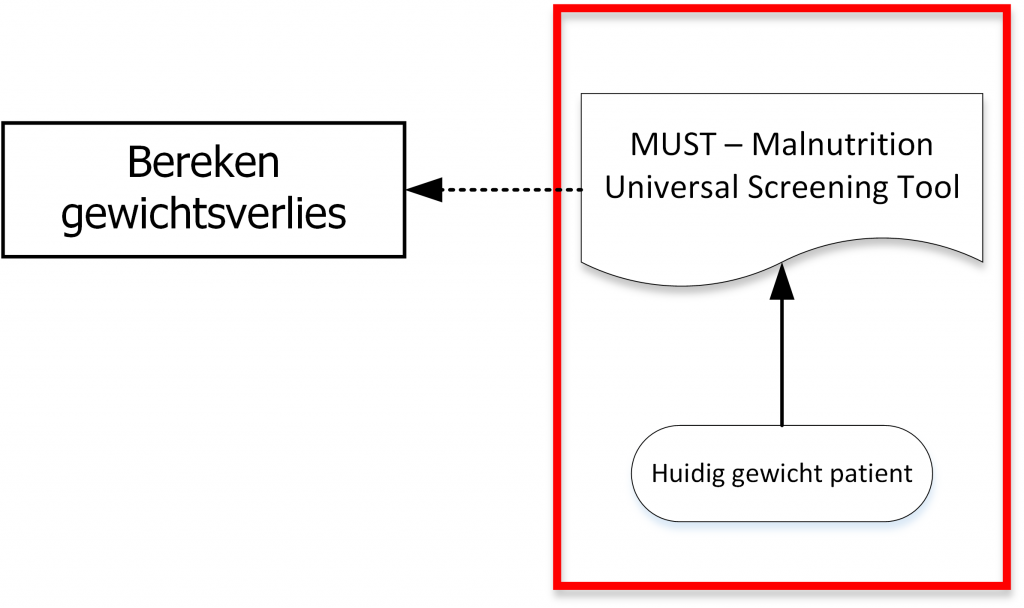
In deze eerste stap dient het touchpoint te worden geanalyseerd ten aanzien van zogenaamde identificatie-woorden. Voorbeelden van veel gebruikte identificatie- woorden zijn: “bepaal”, “bereken”, “diagnoseer”, “plan”, “configureer”, “classificeer”, “beoordeel”, “monitor”, “voorspel”, “configureer”, “toewijzen”, “rooster”, “ontwerp” en “modeleer”. Een identificatie-woord wordt vaak opgevolgd met een zelfstandignaamwoord of een ‘zelfstandignaamwoord groep’. Voorbeelden hiervan zijn: “body mass index”, “(hoogte van de) kinderbijslag”, “risicoprofiel”.
Wanneer een touchpoint een identificatiewoord plus een zelfstandignaamwoord bevat, bijvoorbeeld “bereken body mass index”, dan dienen beide voor verdere analyse gemarkeerd te worden. Wat betekent ‘gemarkeerd voor verdere analyse’ in dit geval? In de praktijk betekent dit vaak dat ze gehighlight of geacceerd worden. Op papier kan dit met een markeerstift en wanneer er software wordt gebruikt kan dit met de functionaliteit die de tooling biedt.
Stap 2: Identificeren zelfstandignaamwoorden
Vaak bevatten formulieren, websites en andere touchpoints geen identificatie-woorden zoals: “bepaal” en “bereken”. Daarom dient het touchpoint ook gecontroleerd te worden op zelfstandignaamwoorden zonder identificatie-woorden. De vraag die de modelleur bij elk zelfstandignaamwoord zich dient af te vragen is: “is het logisch dat ik voor dit zelfstandignaamwoord een identificatie-woord plaats?”
Bijvoorbeeld wanneer een formulier de term “body mass index” bevat, dan kan hiervoor gezet worden: “bereken”. In dat geval dient “body mass index” voor verdere analyse gemarkeerd te worden. Wanneer je twijfelt, is een eenvoudig, maar in veel gevallen correct ezelbruggtje om in de initiale analyse elk zelfstandignaamwoord te markeren voor verdere analyse.
Stap 3: Identificeren onzichtbare feittypen**
De eerste twee sub-stappen zijn relatief eenvoudig uit te voeren. De derde sub-stap is wat ingewikkelder omdat er op zoek gegaan dient te worden naar ‘onzichtbare’ of ‘verborgen’ feittypen. Formulieren zijn zelden perfect voor analyse doeleinden en vaak staan de identificatie-woorden niet letterlijk benoemd, maar het komt ook vaak voor dat er zelfs geen zelfstandignaamwoorden staan genoemd. In dat geval zijn de feittypen: ‘onzichtbaar’ of ‘verborgen’. Een onzichtbaar feittype is een feittype waarvan de feitwaarde(n) wel is/zijn benoemd maar het bijbehorende feittype niet is benoemd.
Een ervaren analyst zal op een gegeven moment geen onderscheid meer maken tussen deze drie stappen. Dit stappenplan geeft de onervaren analyst houvast in het maken van een DRD.
2.1 Voorbeeld: Initiele analyse van de/het touchpoint(s)
De drie sub-stappen voor de initiele analyse: 1) Identificeren Identificatie-woorden, 2) Identificeren zelfstandignaamwoorden en 3) Identificeren onzichtbare feittypen worden nu toegepast op het intakeformulier van Kees.
Stap 1 – Identificeren Identificatie-woorden
Wanneer stap 1, identificeren identificatiewoorden, wordt uitgevoerd dan valt het meteen op dat de woorden“bepaal”, “bereken”, “diagnoseer” en “plan” ontbreken. Zoals eerder benoemd zal dit vaak het geval zijn. Hiermee is de eerste sub-stap wel voltooid en dient de tweede sub-stap te worden uitgevoerd.
Stap 2 – Identificeren Zelfstandignaamwoorden
In de tweede sub-stap worden de zelfstandignaamwoorden op het formulier geidentificeerd, zie Figuur 2.

Figuur 2. analyseresultaten arcering zelfstandig naamwoorden
Het resultaat hiervan is de identificatie van vijf zelfstandig naamwoorden, zie Figuur 3:
![]()
Figuur 3. gemarkeerde zelfstandig naamwoorden (set van kandidaat beslissingen en feittypen – deel 1)
Stap 3 – Identificeren onzichtbare feittype
In de vorige twee sub-stappen zijn de elementen zoals getoond in Figuur 3 gemarkeerd. De vraag die nu beantwoord dient te worden is of alle elementen die we nodig hebben voor de analyse zijn geidentificeerd (gemarkeerd)? Om deze vraag te kunnen beantwoorden dient er nog één stap uitgevoerd te worden. De analyse van de onzichtbare feittype (sub-stap 3).
Een onzichtbaar feitype identificeer je met behulp van de zichtbare feitwaarde(n). De modelleur dient daarom eerst de zichtbare feitwaarden te identificeren. Met betrekking tot het intakeformulier voor Kees zijn er acht sets van feitwaarden te identificeren, zie tabel 1 tot en met 4.
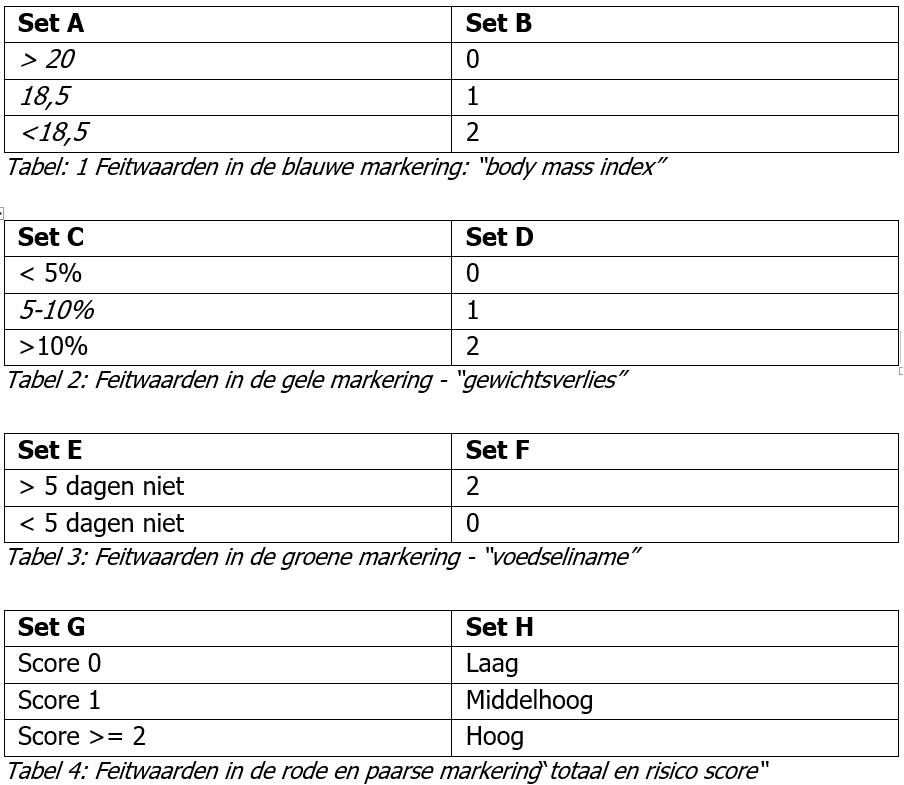
Met betrekking tot body mass index staat er twee sets van feitwaarde benoemd: Set A en Set B. Voor elke set van feitwaarden dient de volgende vraag gesteld te worden:
Welk feittype representeren deze feitwaarden?
Het antwoord op deze vraag is in het geval van set A: de “body mass index” van een persoon. De volgende vraag is nu:
- Staat dit feittype al genoemd in de set van kandidaat beslissingen en feittypen dat is gemaakt na het uitvoeren van sub-stap 1 en sub-stap 2?
In dit specifieke geval is het antwoord op deze vraag: “ja” en dient “body mass index” dus niet (voor een tweede keer) toegevoegd te worden. Beide vragen dienen ook gesteld te worden voor feitwaarde Set B: “Welk feittype representeren deze feitwaarden?“ en“Staat dit feittype al genoemd in de set van kandidaat beslissingen en feittypen gemaakt na het uitvoeren van sub-stap 1 en sub-stap 2?” Het feittype die deze feitwaarden representeren is: “risicopunten BMI” en dit feittype staat niet in de huidige set van kandidaat beslissingen en feittypen, zie Figuur 3, vermeldt. Daarom dient deze te worden toegevoegd, zie Figuur 4.

Figuur 4. Set van kandidaat beslissingen en feittypen – deel 2
De hierboven besproken excersitie dient nu herhaald te worden voor het vak waarin het feittype gewichtsverlies is weergegeven, het vak waarin voedsel inname is weergegeven en de twee vakken waarin totaal en risico score zijn weergegeven, zie tabel 2 tot en met 4. Hierdoor worden “percentage gewichtsverlies” en “aantal dagen geen voedseliname” toegevoegd aan de set van kandidaat beslissingen en feittypen, zie Figuur 5.

Figuur 5. Set van kandidaat beslissingen en feittypen – deel 3
Uit de bovenstaande analyse en analyseresultaten blijkt dat er een aantal stappen nodig zijn om tot het gewenste eindresultaat te komen. Dit komt omdat de formulieren, website en andere touchpoints ontwikkeld worden met gebruikersgemak in het achterhoofd en niet het gemak om te analyseren en modelleren. Om toch een doorkijk te geven hoe een formulier er voor de modelleur ideaal zou uitzien, zie Figuur 6. Zoals in het hiervoor besproken voorbeeld is gedemonstreerd is dit niet altijd het geval en daarom dienen de voorgaande drie sub-stappen altijd netjes doorlopen te worden.
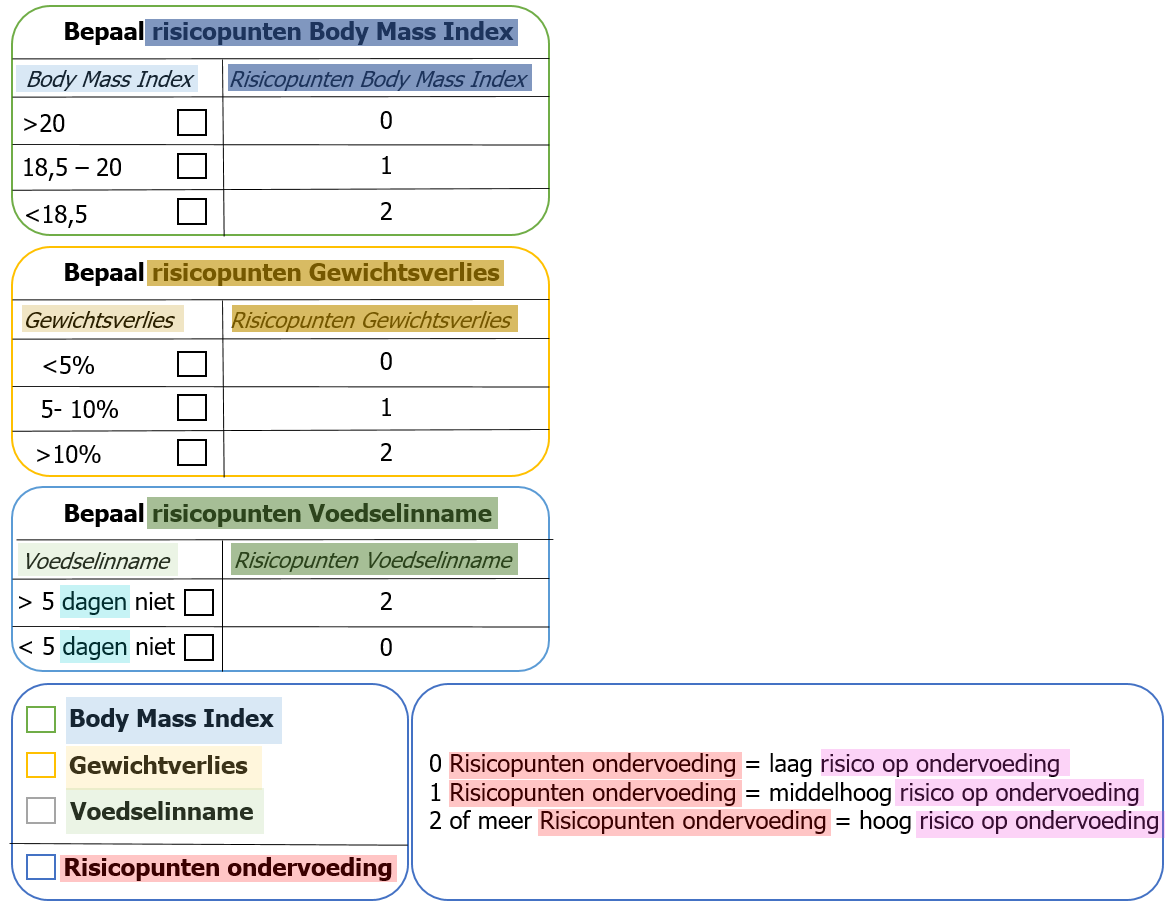
Figuur 6. Set van kandidaat beslissingen en feittypen ’meest optimale’ formulier markering zelfstandig naamwoorden
Identificeren ‘eind’ beslissing?
Het identificeren van de ‘eind’ beslissing kan nogal een “ja duh-gevoel” (populair taalgebruik onder jongeren op dit moment) oproepen. De reden dat dit gevoel wordt opgeroepen is omdat het antwoord vaak nogal voor de hand ligt. En wanneer je als modelleur vaker DRD’s maakt zal ook deze vraag snel een automatisme worden. Maar voor een beginned modelleur is het handig om expliciet stil te staan bij deze vraag.
De ‘eind’ beslissing is de beslissing die uiteindelijk beantwoord moet worden tijdens het scenario of de case. In de huidige case is de beslissing: “bepaal het risico op ondervoeding“.
Tot zover deel 2 in een serie van 4. In het volgende artikel gaan we verder met de volgende stappen van scenario gebaseerd eliciteren.
Mede-Auteur: Koen Smit
**Een feittype is in de context van dit artikel een synoniem voor een gegeven zoals genoemd in het vorige deel: Introductie Decision Model and Notation (DMN): Deel 1. Natuurlijk is er wel degelijk een verschil tussen beide concepten te onderkennen, maar dit houden we voor de eenvoud en leesbaarheid buiten beschouwing. De verschillen en relaties tussen beide concepten wordt uitgelegd in het artikel: Basis Business Rules Management.